

Netflix gastó aproximadamente $ 15 mil millones para producir contenido original de clase mundial en 2019. Cuando hay tanto en juego, es primordial habilitar a nuestro negocio con conocimientos críticos que ayuden a planificar, determinar el gasto y contabilizar todo el contenido de Netflix. Estos conocimientos pueden incluir:
- ¿Cuánto deberíamos gastar el próximo año en películas y series internacionales?
- ¿Tenemos la tendencia de superar nuestro presupuesto de producción y alguien necesita intervenir para mantener las cosas en marcha?
- ¿Cómo programamos un catálogo con años de anticipación con datos, intuición y análisis para ayudar a crear la mejor lista posible?
- ¿Cómo producimos datos financieros para contenido en todo el mundo e informamos a Wall Street?
De manera similar a la forma en que los capitalistas de riesgo ajustan rigurosamente su ojo para las buenas inversiones, el estatuto del equipo de ingeniería de finanzas de contenido es ayudar a Netflix a invertir, rastrear y aprender de nuestras acciones para que continuamente hagamos mejores inversiones en el futuro.
Abraza los eventos
Desde el punto de vista de la ingeniería, cada aplicación financiera se modela e implementa como un microservicio. Netflix adopta la gobernanza distribuida y fomenta un enfoque de aplicaciones impulsado por microservicios, lo que ayuda a lograr el equilibrio adecuado entre la abstracción de datos y la velocidad a medida que la empresa escala. En un mundo simple, los servicios pueden interactuar a través de HTTP sin problemas, pero a medida que escalamos, evolucionan hacia un gráfico complejo de interacciones sincrónicas basadas en solicitudes que pueden conducir potencialmente a un estado / cerebro dividido e interrumpir la disponibilidad.
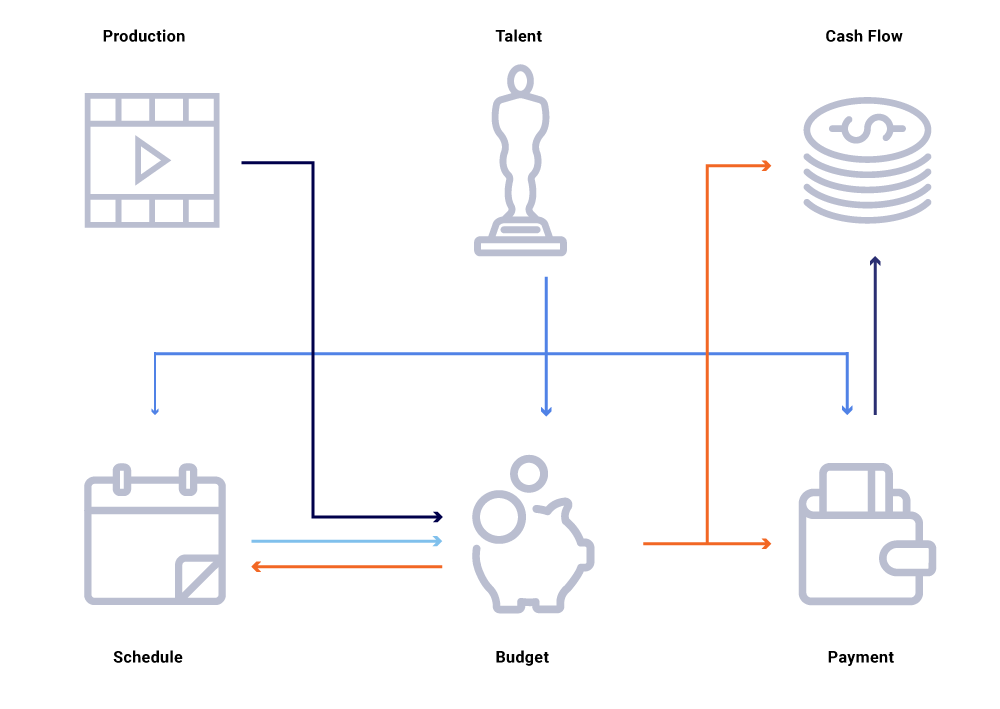
Considere en el gráfico anterior de entidades relacionadas, un cambio en la fecha de producción de un programa. Esto impacta nuestra lista de programación, que a su vez influye en los proyectos de flujo de caja, pagos de talento, presupuestos para el año, etc. A menudo, en una arquitectura de microservicio, algún porcentaje de falla es aceptable. Sin embargo, una falla en cualquiera de las llamadas de microservicio para Ingeniería de Financiamiento de Contenidos daría lugar a una gran cantidad de cálculos desincronizados y podría resultar en datos desfasados por millones de dólares. También conduciría a problemas de disponibilidad a medida que el gráfico de llamadas se expande y causa puntos ciegos al intentar rastrear y responder de manera efectiva preguntas comerciales, tales como: ¿Por qué las proyecciones de flujo de caja se desvían de nuestro programa de lanzamiento? ¿Por qué la previsión para el año en curso no tiene en cuenta los programas que están en desarrollo activo? ¿Cuándo podemos esperar que nuestros informes de costos reflejen con precisión los cambios anteriores?
Repensar las interacciones de servicio como flujos de intercambio de eventos, en contraposición a una secuencia de solicitudes sincrónicas, nos permite construir una infraestructura que es inherentemente asincrónica. Promueve el desacoplamiento y proporciona trazabilidad como ciudadano de primera clase en una red de transacciones distribuidas. Los eventos son mucho más que disparadores y actualizaciones. Se convierten en la corriente inmutable a partir de la cual podemos reconstruir todo el estado del sistema.
Avanzar hacia un modelo de publicación / suscripción permite que cada servicio publique sus cambios como eventos en un bus de mensajes, que luego puede ser consumido por otro servicio de interés que necesite ajustar su estado del mundo. Dicho modelo nos permite rastrear si los servicios están sincronizados con respecto a los cambios de estado y, en caso contrario, cuánto tiempo antes de que puedan estar sincronizados. Estos conocimientos son extremadamente poderosos cuando se opera un gran gráfico de servicios dependientes. La comunicación basada en eventos y el consumo descentralizado nos ayudan a superar los problemas que generalmente vemos en los grandes gráficos de llamadas sincrónicas (como se mencionó anteriormente).
Netflix abraza Apache Kafka ® como el estándar de facto para su concurso completo, mensajería y procesamiento de flujo necesidades. Kafka actúa como un puente para todas las comunicaciones punto a punto y de Netflix Studio. Nos proporciona la arquitectura multiinquilino de alta durabilidad y escalabilidad lineal necesaria para los sistemas operativos en Netflix. Nuestra oferta interna de Kafka como servicio proporciona tolerancia a fallas, observabilidad, implementaciones multirregionales y autoservicio. Esto hace que sea más fácil para todo nuestro ecosistema de microservicios producir y consumir eventos significativos y liberar el poder de la comunicación asincrónica.
Un intercambio de mensajes típico dentro del ecosistema de Netflix Studio se ve así:
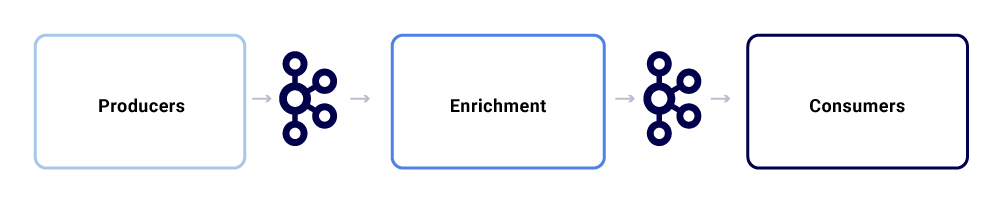
Podemos dividirlos en tres subcomponentes principales.
Productores
Un productor puede ser cualquier sistema que quiera publicar su estado completo o insinuar que una parte crítica de su estado interno ha cambiado para una entidad en particular. Además de la carga útil, un evento debe adherirse a un formato normalizado, lo que hace que sea más fácil de rastrear y comprender. Este formato incluye:
- UUID: identificador único universal
- Tipo: uno de los tipos de creación, lectura, actualización o eliminación (CRUD)
- Ts: marca de tiempo del evento
Las herramientas de captura de datos de cambios (CDC) son otra categoría de productores de eventos que derivan eventos de cambios en la base de datos. Esto puede resultar útil cuando desee que los cambios en la base de datos estén disponibles para varios consumidores. También usamos este patrón para replicar los mismos datos en los centros de datos (para bases de datos maestras únicas). Un ejemplo es cuando tenemos datos en MySQL que necesitan indexarse en Elasticsearch o Apache Solr ™. La ventaja de utilizar CDC es que no impone una carga adicional a la aplicación de origen.
Para los eventos de CDC, el
Enriquecedores
Una vez que los datos existen en Kafka, se les pueden aplicar varios patrones de consumo. Los eventos se utilizan de muchas maneras, incluso como disparadores para cálculos del sistema, transferencia de carga útil para comunicación casi en tiempo real y señales para enriquecer y materializar vistas de datos en memoria.
El enriquecimiento de datos se está volviendo cada vez más común donde los microservicios necesitan la vista completa de un conjunto de datos, pero parte de los datos provienen del conjunto de datos de otro servicio. Un conjunto de datos unido puede resultar útil para mejorar el rendimiento de las consultas o proporcionar una vista casi en tiempo real de los datos agregados. Para enriquecer los datos del evento, los consumidores leen los datos de Kafka y llaman a otros servicios (utilizando métodos que incluyen gRPC y GraphQL) para construir el conjunto de datos unidos, que luego se alimentan a otros temas de Kafka.
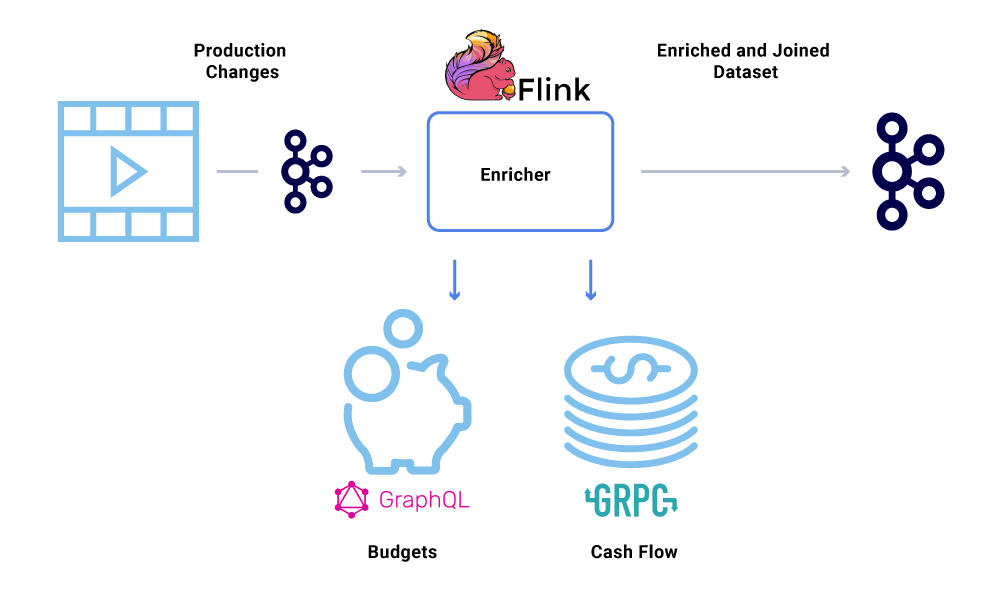
El enriquecimiento se puede ejecutar como un microservicio separado en sí mismo que es responsable de hacer el despliegue y de materializar los conjuntos de datos. Hay casos en los que queremos realizar un procesamiento más complejo, como la creación de ventanas, la sesionización y la gestión de estados. Para tales casos, se recomienda utilizar un motor de procesamiento de flujo maduro sobre Kafka para construir la lógica empresarial. En Netflix, utilizamos Apache Flink ® y RocksDB para realizar el procesamiento de transmisiones. También estamos considerando ksqlDB para propósitos similares.
Orden de eventos
Uno de los requisitos clave dentro de un conjunto de datos financieros es el orden estricto de los eventos. Kafka nos ayuda a lograrlo mediante el envío de mensajes con clave. Cualquier evento o mensaje enviado con la misma clave, tendrá orden garantizado ya que se envían a la misma partición. Sin embargo, los productores aún pueden estropear el orden de los eventos.
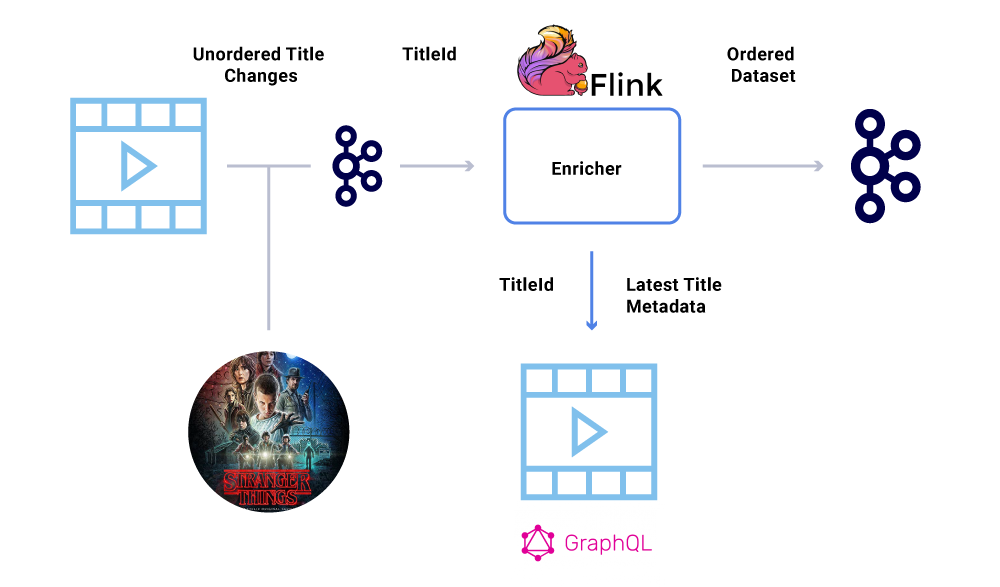
Por ejemplo, la fecha de lanzamiento de «Stranger Things» se trasladó originalmente de julio a junio, pero luego de junio a julio. Por diversas razones, estos eventos podrían escribirse en el orden incorrecto en Kafka (tiempo de espera de la red cuando el productor intentó comunicarse con Kafka, un error de concurrencia en el código del productor, etc.). Un contratiempo en el pedido podría haber tenido un gran impacto en varios cálculos financieros.
Para eludir este escenario, se alienta a los productores a enviar solo el ID principal de la entidad que ha cambiado y no la carga útil completa en el mensaje de Kafka. El proceso de enriquecimiento (descrito en la sección anterior) consulta el servicio de origen con el ID de la entidad para obtener el estado / carga útil más actualizado, proporcionando así una forma elegante de sortear el problema del desorden. Nos referimos a esto como materialización retrasada y garantiza conjuntos de datos ordenados.
Consumidores
Usamos Spring Boot para implementar muchos de los microservicios consumidores que leen de los temas de Kafka. Spring Boot ofrece excelentes consumidores de Kafka integrados llamados Spring Kafka Connectors, que facilitan el consumo y brindan formas fáciles de conectar anotaciones para el consumo y la deserialización de datos.
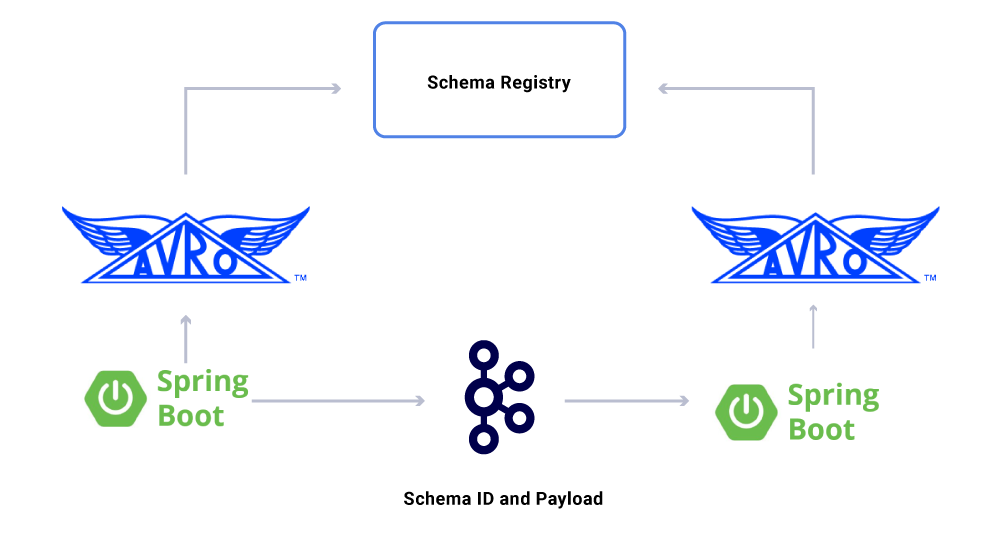
Un aspecto de los datos que aún no hemos discutido son los contratos . A medida que ampliamos nuestro uso de flujos de eventos, terminamos con un grupo variado de conjuntos de datos, algunos de los cuales son consumidos por una gran cantidad de aplicaciones. En estos casos, la definición de un esquema en la salida es ideal y ayuda a garantizar la compatibilidad con versiones anteriores. Para hacer esto, aprovechamos Confluent Schema Registry y Apache Avro ™ para construir nuestros flujos esquematizados para versionar flujos de datos.
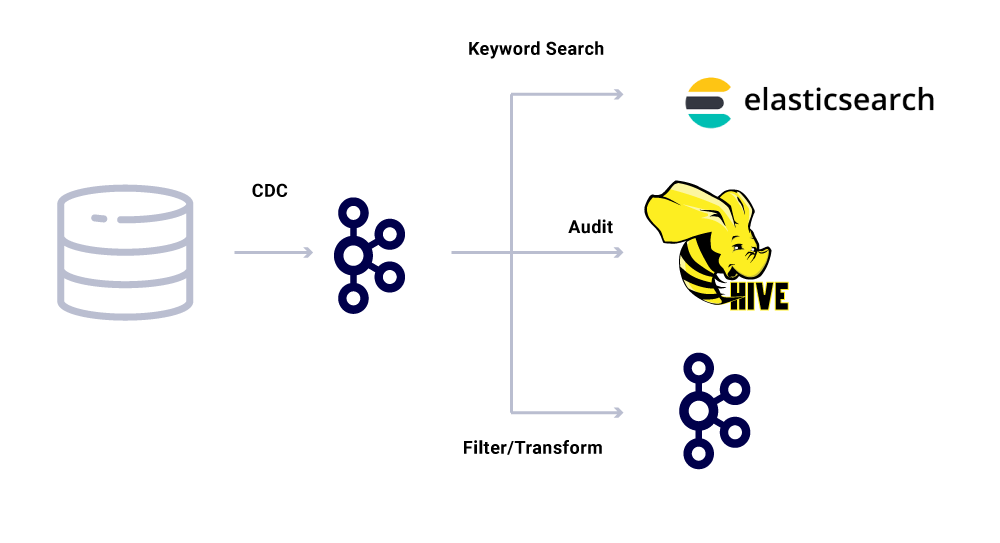
Además de los consumidores de microservicios dedicados, también tenemos sumideros CDC que indexan los datos en una variedad de tiendas para un análisis más detallado. Estos incluyen Elasticsearch para búsqueda de palabras clave, Apache Hive ™ para auditoría y el propio Kafka para un procesamiento posterior posterior. La carga útil de dichos receptores se deriva directamente del mensaje de Kafka mediante el uso del campo ID como clave principal y
Garantías de entrega de mensajes
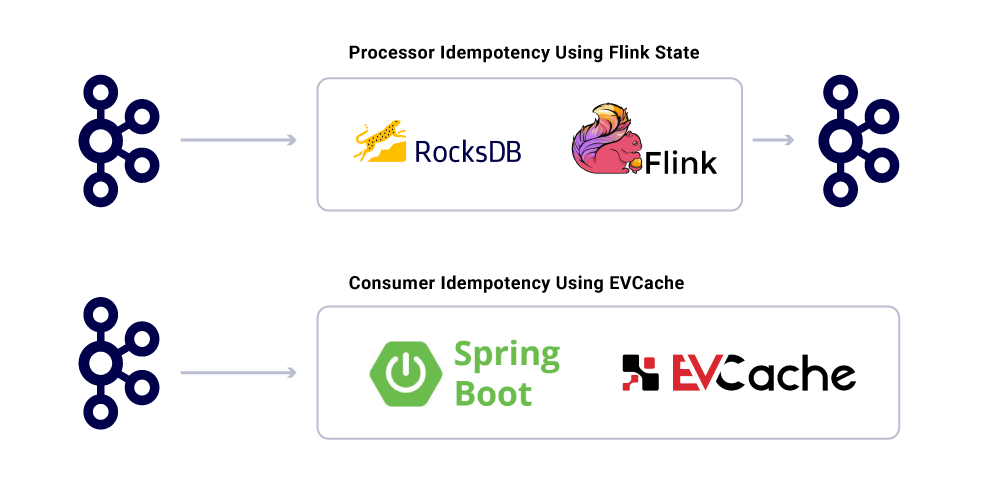
Garantizar una entrega exacta en un sistema distribuido no es trivial debido a las complejidades involucradas y la gran cantidad de piezas móviles. Los consumidores deben tener un comportamiento idempotente para dar cuenta de posibles contratiempos de infraestructura y productores.
A pesar del hecho de que las aplicaciones son idempotentes, no deben repetir operaciones informáticas pesadas para mensajes ya procesados. Una forma popular de garantizar esto es realizar un seguimiento del UUID de los mensajes consumidos por un servicio en una caché distribuida con vencimiento razonable (definido según los Acuerdos de nivel de servicio (SLA). Cada vez que se encuentra el mismo UUID dentro del intervalo de vencimiento, el procesamiento se omite.
El procesamiento en Flink proporciona esta garantía mediante el uso de su gestión de estado interna basada en RocksDB, siendo la clave el UUID del mensaje. Si desea hacer esto únicamente con Kafka, Kafka Streams también ofrece una forma de hacerlo. El consumo de aplicaciones basadas en Spring Boot usa EVCache para lograr esto.
Supervisión de los niveles de servicio de la infraestructura
Es crucial para Netflix tener una vista en tiempo real de los niveles de servicio dentro de su infraestructura. Netflix escribió Atlas para administrar datos de series temporales dimensionales, a partir de los cuales publicamos y visualizamos métricas. Usamos una variedad de métricas publicadas por productores, procesadores y consumidores para ayudarnos a construir una imagen casi en tiempo real de toda la infraestructura.
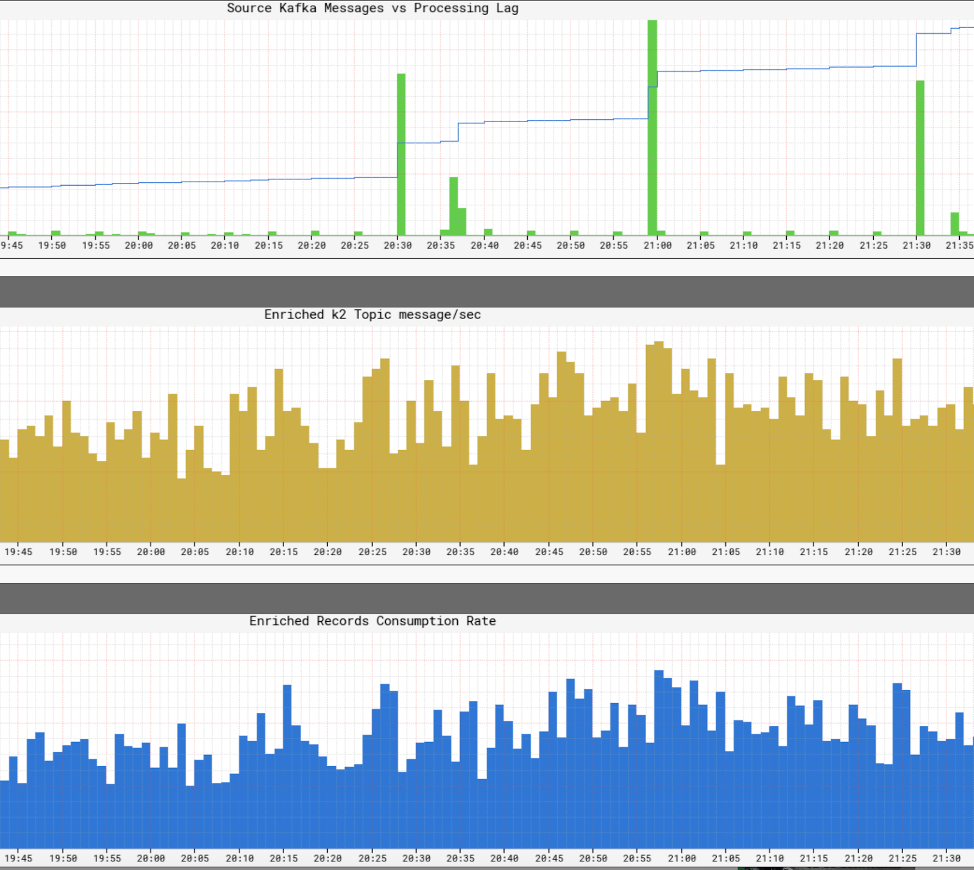
Algunos de los aspectos clave que monitoreamos son:
- SLA de frescura
- ¿Cuál es el tiempo de un extremo a otro desde la producción de un evento hasta que alcanza todos los sumideros?
- ¿Cuál es el retraso de procesamiento para cada consumidor?
- Tasa de transferencia máxima
- ¿Qué tamaño de carga útil podemos enviar?
- ¿Debemos comprimir los datos?
- Particionamiento y paralelismo
- ¿Estamos utilizando nuestros recursos de manera eficiente?
- ¿Podemos consumir más rápido?
- Conmutación por error y recuperación
- ¿Podemos crear un punto de control para nuestro estado y reanudarlo en caso de fallas?
- Contrapresión
- Si no podemos mantenernos al día con el evento firehose, ¿podemos aplicar contrapresión a las fuentes correspondientes sin bloquear nuestra aplicación?
- Distribución de la carga
- ¿Cómo nos ocupamos de las ráfagas de eventos?
- ¿Estamos lo suficientemente aprovisionados para cumplir con el SLA?
FUENTE: https://www.confluent.io/blog/how-kafka-is-used-by-netflix/