
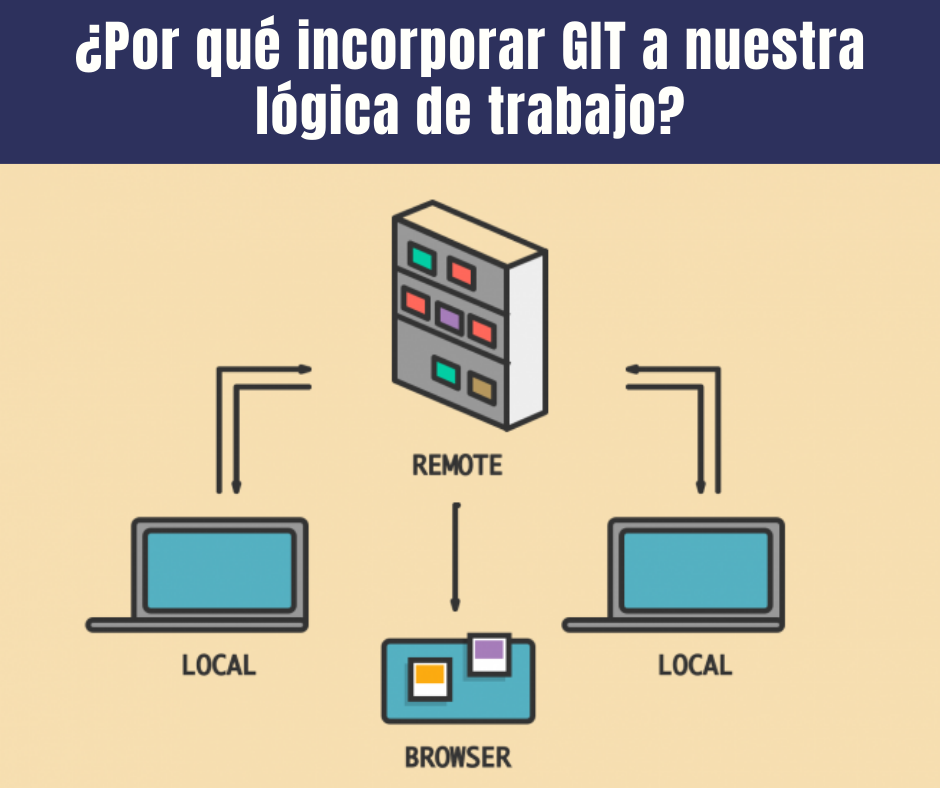
Incorporar GIT a un equipo trae muchas ventajas, pero para aprovechar este software debemos transformar nuestras lógicas y flujos de trabajo.
GIT es un software de control de versiones cuya principal función es mantener un registro de los cambios realizados en archivos. Pero sus utilidades van mucho más allá. Desde hace ya varios años, se ha popularizado GIT también como una herramienta de seguridad. A continuación explicaremos cómo aprovechamos sus funciones y por qué resulta esencial en nuestros proyectos.
Seguridad y Coordinación
Una de las herramientas favoritas en las que nos apoyamos durante el proceso de desarrollo de un sitio es GIT. Honestamente, no hace que el código sea mejor ni más ordenado. Tampoco es porque que sea simple mantener un grupo más o menos elevado de repositorios; pues, sin ser algo complejo, es necesario mantener cierto nivel de convenciones que nos den orden y coherencia. No obstante, la razón verdadera por la que amamos GIT es porque nos da seguridad, mucha seguridad.
Hace unos años atrás usábamos SVN, pero era un lío; bastaba un mínimo de complejidad en un proyecto para que el repositorio se estropeara y todo lo demás fallara. Hoy, con 150 proyectos distintos respaldados en nuestra cuenta de Bitbucket, tenemos un workflow sencillo que se mantiene organizado de forma lógica y que en las etapas de desarrollo o mantención nos facilita la coordinación de los proyectos más complejos.
Evitando errores frecuentes
El equipo de desarrollo en IDA siempre ha sido relativamente pequeño; pocas veces ha superado las 5 personas. Sin embargo, más allá la cantidad de personas que lo integran en un momento determinado, es importante considerar cómo funciona y se organiza para cumplir con los requerimientos que tiene a diario; y entender, a la vez, cuáles son las dificultades a las que normalmente se enfrenta.
Una problemática común en cualquier compañía es la rotación de personal. Si llega un nuevo integrante al equipo bastará con agregarlo a un team para tenga acceso a todos los proyectos en los que trabajará, pero más importante; tendrá acceso a la última versión productiva y a todos los trabajos en progreso que ese proyecto tenga, sin posibilidad de confusiones y errores. Incluso, será igual de sencillo tener acceso al trabajo en progreso de un desarrollador que deje la compañía y quitarle los accesos cuando ya se haya ido.
Otro punto de complicación es que la tendencia al desorden es la norma. En el caso de IDA es normal que un desarrollador entre y salga de un proyectos acorde a los requerimientos que este tenga y, probablemente, dependiendo de la etapa en la que se encuentre.
Por ejemplo, es normal que el desarrollador cambie al pasar de la etapa de maquetación front a la etapa de implementación del backend. A la vez, en etapa de beta o de mantención es probable que haya más de una persona trabajando en el mismo proyecto. Sin GIT, léase Sistema de Control de Versiones, eso es un lío de proporciones bíblicas. Varias personas haciendo en paralelo muchos cambios en muchos archivos termina siempre de la misma forma: caos, pérdida del trabajo por sobrescritura y muchas horas desperdiciadas de trabajo por descoordinación.
Sin duda, el desorden de un equipo y la pérdida de horas es un gran problema para cualquier empresa, por lo que significa en términos de costos, pero lo peor es que de manera casi inevitable llegará algún error al sitio productivo, ya sea porque se pierda una modificación reciente o porque se suba algo que aún no esté aprobado para su paso a producción. Eso es fatal.
A pesar de todo, el mayor temor de un desarrollador no es el desorden (aunque debiese serlo), sino que hackeen alguno de los sitios que tiene en producción. El hackeo de un sitio plantea múltiples problemas en paralelo: qué modificaron, por dónde entraron, cuánto me demoraré en restaurar el sistema si no sé qué modificaron, cómo evito que pase de nuevo si no sé cómo entraron, etc.
Si bien GIT no es un sistema pensado para la seguridad, puede ser de mucha ayuda en esa tarea. Si ahí tengo la última versión de mis sitios, ¿no es lógico pensar que si me hackean puedo usar GIT para saber qué cambiaron y para restaurar prácticamente todo el sitio con su última versión limpia?
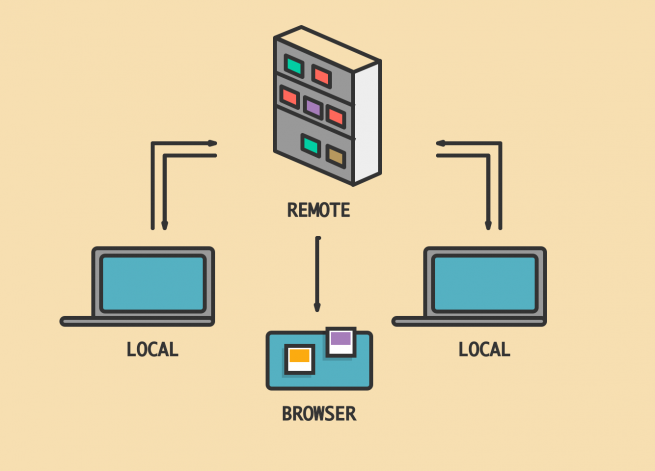
Perfeccionando el flujo de trabajo
GIT es un sistema que nos permite gestionar las distintas versiones, etapas, ramas y estados de un proyecto en un grupo de trabajo mediante un repositorio centralizado en la nube. Su uso, en principio, es muy sencillo. Uno realiza un cambio en un archivo, lo guarda en un commit y lo sube al repositorio oncloud mediante un push. Pero solo puedo hacer tal push si tengo la última versión de todo el proyecto, es decir, que haya hecho un fetch y un pull de los cambios que otros hayan hecho, dejándole al sistema la responsabilidad de hacer la mezcla automática de todos los cambios hechos por los distintos miembros del equipo.
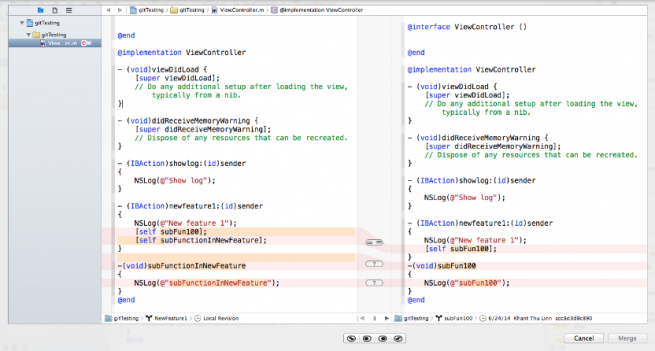
Si hay un caso que el sistema no pueda determinar automáticamente cuál versión dejar, por ejemplo, que se haya modificado exactamente la misma línea por dos personas en paralelo, surge lo que se denomina un “conflicto” y será un humano quien realice una mezcla manual y determine lo que se mantiene y lo que sobrescribe o elimina.
Si bien la lógica que planeta es sencilla, requiere establecer un flujo de trabajo ordenado que permita tomar decisiones prácticamente sin error. Para ello se hace el uso de ramas de desarrollo donde se pueden trabajar las modificaciones de un proyecto sin afectar a la rama principal o master, que vendría a ser la versión estable final disponible a los usuarios.
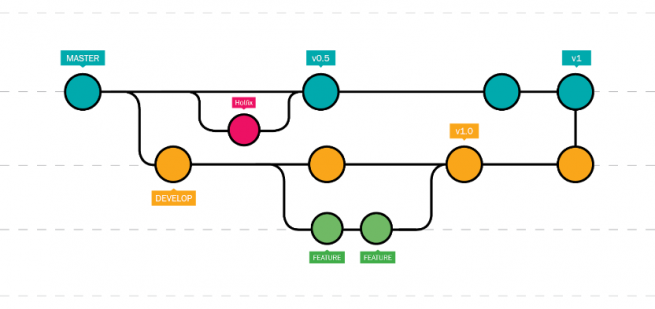
Básicamente es este workflow y la posibilidad de tener todo ordenado en ramas lo que prácticamente anula la posibilidad de cometer errores en la versión de producción o aquello que los usuarios ven. Por otra parte, al estar todo centralizado en un repositorio en la nube, permite que cualquier miembro del equipo, nuevo o antiguo, pueda tener una copia de todo el código, su historial y sus distintas ramas en cosa de minutos. Esta misma capacidad es usada para hacer lo que se denomina el deploy de un sitio a su ambiente productivo en muy poco tiempo y, en la etapa de mantención, de las sucesivas modificaciones que se irán realizando, independiente de cuándo el cliente solicitó el cambio, de cuando aprobó su paso a producción y de si entre medio solicitó o aprobó otras modificaciones.
Si fuese el caso que uno o varios archivos son modificados en el ambiente productivo sin haber pasado por el flujo de trabajo, con un par de comandos simples podremos conocer el estado de la rama master, compararla con otras ramas o con lo que está en el repositorio remoto y determinar qué archivos y qué líneas han sufrido modificaciones a la mala. En el caso de un hackeo bastará hacer un git stash para eliminar tales cambios y volver al último commit disponible en la rama master local del ambiente productivo. Todo susceptible de ser automatizado con “deamons” en el servidor o con “crontabs” que se ejecutan cada cierto tiempo”.
Nuestra experiencia en GIT
Evidentemente no todos los equipos de desarrollo se organizan igual y no todos los repositorios son necesariamente iguales. Si bien GIT impone ciertas lógicas básicas, es lo suficientemente versátil como herramienta para ser adaptado a distintos workflows; pero la clave está en tener un flujo de trabajo claro, sencillo y que todos los miembros del equipo entiendan y cumplan.
En el caso de IDA lo primero es que clasificamos cada repositorio usando un prefijo en el nombre del mismo. De esta forma sabemos inmediatamente si el repositorio obedece a una configuración de servidor, un sitio, un front html o un simple experimento de laboratorio. Cuando se trata de un sitio o network (conjunto de sitios montados sobre WordPress MU) trabajamos con tres ramas: master, QA y develop. Siguiendo las recomendaciones de bitbucket, además usamos ramas temporales mediante la funcionalidad de “features” que se mezclan con la rama “develop” y que se eliminan automáticamente una vez que el desarrollador termina y cierra la modificación solicitada. Esto permite que se realicen todas las modificaciones paralelas imaginables casi sin riesgo de cometer un error. Todo estos cambios se prueban sobre un ambiente o servidor de desarrollo y teniendo el ok interno de la jefa de proyectos, se pasan a la rama QA y se hace el deploy al ambiente de QA donde será el cliente el que hará las pruebas respectivas. Aprobadas por el cliente, se repite el proceso con la rama “master” y el ambiente productivo.
Es importante destacar que el hecho de que cualquier miembro del equipo puede ser asignado a un proyecto en cualquier momento, tiene como consecuencia directa que nos obliga a ordenar y mejorar nuestro propio código; cualquiera puede corregir o mejorar el trabajo del compañero, cualquiera puede aprender mirando lo que el más avanzado ha hecho. La idea de trabajo colaborativo hecha práctica.
FUENTE: https://blog.ida.cl/desarrollo/git-workflow/