

Introducción a la recolección de basura, métricas y compensaciones
El componente de HotSpot JVM que administra el montón de aplicaciones de su aplicación se denomina recolector de elementos no utilizados (GC). Un GC gobierna todo el ciclo de vida de los objetos del montón de la aplicación, comenzando cuando la aplicación asigna memoria y continuando hasta reclamar esa memoria para su posible reutilización más adelante.
A un nivel muy alto, la funcionalidad más básica de los algoritmos de recolección de basura en la JVM son las siguientes:
Tras una solicitud de asignación de memoria de la aplicación, el GC proporciona memoria. Siempre que la memoria sea lo más rápida posible.
El GC detecta memoria que la aplicación nunca volverá a usar. Nuevamente, este mecanismo debe ser eficiente y no tomar una cantidad de tiempo indebida. Esta memoria inalcanzable también se denomina comúnmente basura.
Luego, el GC proporciona esa memoria nuevamente a la aplicación, preferiblemente «a tiempo», es decir, rápidamente.
Hay muchos más requisitos para un buen algoritmo de recolección de basura, pero estos tres son los más básicos y suficientes para esta discusión.
Hay muchas maneras de satisfacer todos estos requisitos, pero desafortunadamente no existe una bala de plata ni un algoritmo único para todos. Por esta razón, el JDK proporciona algunos algoritmos de recolección de basura para elegir, y cada uno está optimizado para diferentes casos de uso. Su implementación dicta aproximadamente el comportamiento de una o más de las tres métricas de rendimiento principales de rendimiento, latencia y huella de memoria y cómo afectan las aplicaciones Java.
El rendimiento representa la cantidad de trabajo que se puede realizar en una unidad de tiempo determinada. En términos de esta discusión, es preferible un algoritmo de recolección de basura que realice más trabajo de recolección por unidad de tiempo, lo que permite un mayor rendimiento de la aplicación Java.
La latencia da una indicación de cuánto tiempo lleva una sola operación de la aplicación. Un algoritmo de recolección de basura centrado en la latencia intenta minimizar el impacto de la latencia. En el contexto de un GC, las preocupaciones clave son si su funcionamiento induce pausas, el alcance de las pausas y la duración de las pausas.
La huella de memoria en el contexto de un GC significa cuánta memoria adicional más allá del uso de la memoria del montón de Java de la aplicación que necesita el GC para un funcionamiento adecuado. Los datos utilizados únicamente para la gestión del montón de Java se quitan de la aplicación; si la cantidad de memoria que usa el GC (o, más generalmente, la JVM) es menor, se puede proporcionar más memoria al montón de Java de la aplicación.
Estas tres métricas están conectadas: un recopilador de alto rendimiento puede afectar significativamente la latencia (pero minimiza el impacto en la aplicación) y viceversa. Un menor consumo de memoria puede requerir el uso de algoritmos que son menos óptimos en las otras métricas. Los recopiladores de menor latencia pueden realizar más trabajo simultáneamente o en pequeños pasos como parte de la ejecución de la aplicación, lo que consume más recursos del procesador.
Esta relación a menudo se grafica en un triángulo con una métrica en cada esquina, como se muestra en la Figura 1. Cada algoritmo de recolección de elementos no utilizados ocupa una parte de ese triángulo en función de dónde se dirige y en qué es mejor.
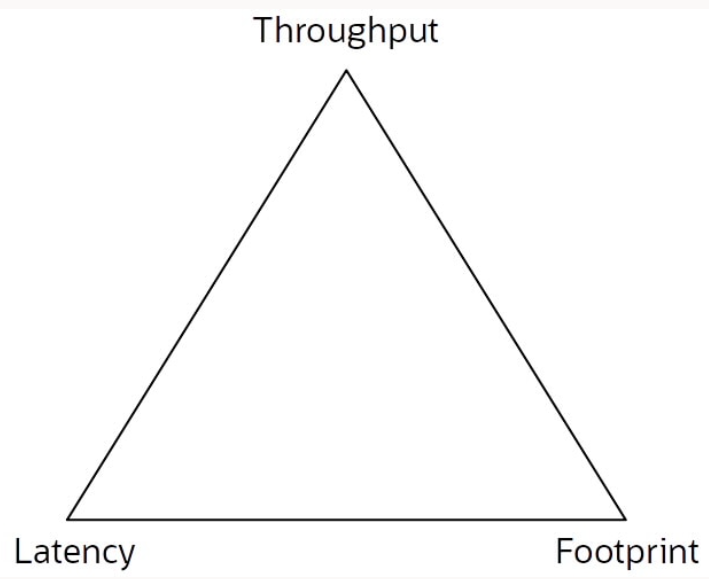
Figura 1. El triángulo de métricas de rendimiento de GC
Intentar mejorar un GC en una o más de las métricas a menudo penaliza a los demás.
Los GC de OpenJDK en JDK 18
OpenJDK proporciona un conjunto diverso de cinco GC que se centran en diferentes métricas de rendimiento. La Tabla 1 enumera sus nombres, su área de enfoque y algunos de los conceptos básicos utilizados para lograr las propiedades deseadas.
Tabla 1. Los cinco GC de OpenJDK
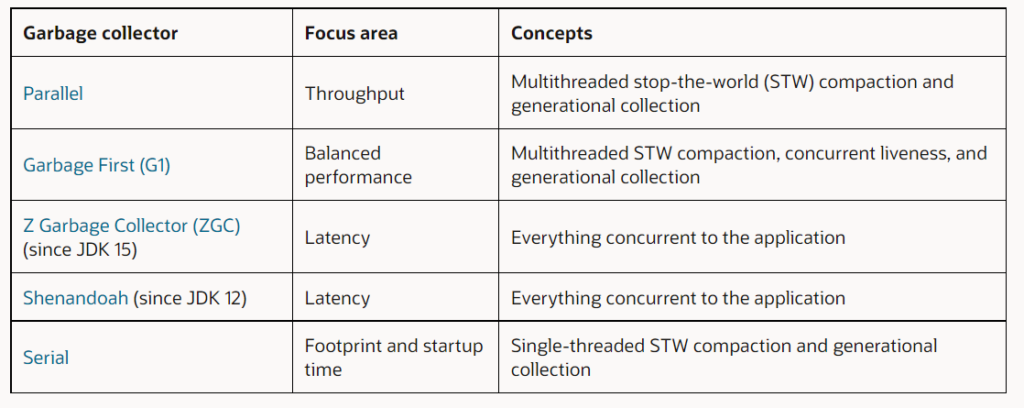
El GC paralelo es el colector predeterminado para JDK 8 y versiones anteriores. Se enfoca en el rendimiento tratando de hacer el trabajo lo más rápido posible con una consideración mínima de la latencia (pausas).
Parallel GC libera memoria evacuando (es decir, copiando) la memoria en uso a otras ubicaciones en el montón de forma más compacta, dejando grandes áreas de memoria libre dentro de las pausas de STW. Las pausas de STW ocurren cuando no se puede satisfacer una solicitud de asignación; luego, la JVM detiene la aplicación por completo, permite que el algoritmo de recolección de basura realice su trabajo de compactación de memoria con tantos subprocesos de procesador como estén disponibles, asigna la memoria solicitada en la asignación y, finalmente, continúa con la ejecución de la aplicación.
El Parallel GC también es un recolector generacional que maximiza la eficiencia de la recolección de basura. Más adelante se discute más sobre la idea de colección generacional.
El G1 GC ha sido el recopilador predeterminado desde JDK 9. G1 intenta equilibrar las preocupaciones de rendimiento y latencia. Por un lado, el trabajo de recuperación de memoria todavía se realiza durante las pausas de STW utilizando generaciones para maximizar la eficiencia, como se hace con Parallel GC, pero al mismo tiempo, intenta evitar operaciones largas en estas pausas.
G1 realiza un trabajo extenso concurrente con la aplicación, es decir, mientras la aplicación se ejecuta utilizando varios subprocesos. Esto reduce significativamente los tiempos máximos de pausa, a costa de cierto rendimiento general.
Los GC ZGC y Shenandoah se centran en la latencia a costa del rendimiento. Intentan hacer todo el trabajo de recolección de basura sin pausas notables. Actualmente ninguno es generacional. Se introdujeron por primera vez en JDK 15 y JDK 12, respectivamente, como versiones no experimentales.
El Serial GC se enfoca en la huella y el tiempo de inicio. Este GC es como una versión más simple y más lenta del Parallel GC, ya que utiliza un solo subproceso para todo el trabajo dentro de las pausas de STW. El montón también está organizado en generaciones. Sin embargo, el Serial GC destaca por su espacio y tiempo de puesta en marcha, lo que lo hace especialmente adecuado para aplicaciones pequeñas y de corta duración debido a su complejidad reducida.
OpenJDK proporciona otro GC, Epsilon, que omití de la Tabla 1. ¿Por qué? Debido a que Epsilon solo permite la asignación de memoria y nunca realiza ninguna recuperación, no cumple con todos los requisitos para un GC. Sin embargo, Epsilon puede ser útil para algunas aplicaciones muy estrechas y de nicho especial.
Breve introducción al G1 GC
El G1 GC se introdujo en la actualización 14 de JDK 6 como una función experimental y fue totalmente compatible a partir de la actualización 4 de JDK 7. G1 ha sido el recopilador predeterminado para HotSpot JVM desde JDK 9 debido a su versatilidad: es estable, maduro , muy activamente mantenido, y se está mejorando todo el tiempo. Espero que el resto de este artículo se lo demuestre.
¿Cómo logra G1 este equilibrio entre rendimiento y latencia?
Una técnica clave es la recolección de basura generacional. Aprovecha la observación de que los objetos asignados más recientemente son los que tienen más probabilidades de recuperarse casi de inmediato (mueren rápidamente). Entonces, G1, y cualquier otro GC generacional, divide el almacenamiento dinámico de Java en dos áreas: una llamada generación joven en la que se asignan inicialmente los objetos y una generación anterior donde se colocan los objetos que viven más que unos pocos ciclos de recolección de basura para la generación joven. para que puedan recuperarse con menos esfuerzo.
La generación joven suele ser mucho más pequeña que la generación anterior. Por lo tanto, el esfuerzo para recopilarlo, más el hecho de que un GC de seguimiento como G1 procesa solo objetos accesibles (en vivo) durante las recopilaciones de la generación joven, significa que el tiempo dedicado a la recolección de basura de la generación joven generalmente es corto y se necesita mucha memoria. recuperado al mismo tiempo.
En algún momento, los objetos de vida más larga se trasladan a la generación anterior.
Por lo tanto, de vez en cuando, existe la necesidad de recolectar basura y recuperar la memoria de la generación anterior a medida que se llena. Dado que la generación anterior suele ser grande y, a menudo, contiene una cantidad significativa de objetos vivos, esto puede llevar bastante tiempo. (Por ejemplo, las colecciones completas de Parallel GC a menudo tardan mucho más que sus colecciones de generación joven).
Por esta razón, G1 divide el trabajo de recolección de basura de generación anterior en dos fases.
G1 primero rastrea a través de los objetos activos al mismo tiempo que la aplicación Java. Esto mueve una gran parte del trabajo necesario para reclamar memoria de la generación anterior fuera de las pausas de recolección de elementos no utilizados, lo que reduce la latencia. La recuperación de memoria real, si se realiza de una sola vez, consumiría mucho tiempo en montones de aplicaciones grandes.
Por lo tanto, G1 recupera memoria de forma incremental de la generación anterior. Después del rastreo de objetos vivos, para cada una de las próximas colecciones regulares de la generación joven, G1 compacta una pequeña parte de la generación anterior además de toda la generación joven, recuperando la memoria allí también con el tiempo.
Reclamar la generación anterior de forma incremental es un poco más ineficiente que hacer todo este trabajo a la vez (como lo hace el GC paralelo) debido a las imprecisiones en el seguimiento a través del gráfico de objetos, así como a la sobrecarga de tiempo y espacio para administrar las estructuras de datos de soporte para las recolecciones de elementos no utilizados incrementales. , pero disminuye significativamente el tiempo máximo de permanencia en las pausas. Como guía aproximada, los tiempos de recolección de elementos no utilizados para las pausas de recolección de elementos no utilizados incrementales toman aproximadamente el mismo tiempo que los que recuperan solo la memoria de la generación joven.
Además, puede establecer el objetivo de tiempo de pausa para estos dos tipos de pausas de recolección de elementos no utilizados a través de la opción de línea de comandos MaxGCPauseMillis; G1 intenta mantener el tiempo empleado por debajo de este valor. El valor predeterminado para esta duración es de 200 ms. Eso podría o no ser apropiado para su aplicación, pero es solo una guía para el máximo. G1 mantendrá los tiempos de pausa por debajo de ese valor si es posible. Por lo tanto, un buen primer intento de mejorar los tiempos de pausa es intentar disminuir el valor de MaxGCPauseMillis.
Progreso de JDK 8 a JDK 18
Ahora que presenté los GC de OpenJDK, detallaré las mejoras que se han realizado en las tres métricas (rendimiento, latencia y huella de memoria) para los GC durante las últimas 10 versiones de JDK.
Ganancias de rendimiento para G1. Para demostrar las mejoras en el rendimiento y la latencia, este artículo utiliza el punto de referencia SPECjbb2015. SPECjbb2015 es un punto de referencia común de la industria que mide el rendimiento del servidor Java mediante la simulación de una combinación de operaciones dentro de una empresa de supermercados. El benchmark proporciona dos métricas.
maxjOPS corresponde al número máximo de transacciones que el sistema puede proporcionar. Esta es una métrica de rendimiento.
CriticaljOPS mide el rendimiento bajo varios acuerdos de nivel de servicio (SLA), como los tiem
pos de respuesta, de 10 ms a 100 ms.
Este artículo usa maxjOPS como base para comparar el rendimiento de las versiones de JDK y las mejoras reales en el tiempo de pausa para la latencia. Si bien los valores de jOPS críticos son representativos de la latencia inducida por el tiempo de pausa, existen otras fuentes que contribuyen a esa puntuación. La comparación directa de los tiempos de pausa evita este problema.
La figura 2 muestra los resultados de maxjOPS para G1 en modo compuesto en un montón de Java de 16 GB, graficados en relación con JDK 8 para JDK 11 y JDK 18. Como puede ver, las puntuaciones de rendimiento aumentan significativamente simplemente al pasar a versiones posteriores de JDK. JDK 11 mejora alrededor de un 5 % y JDK 18 alrededor de un 18 %, respectivamente, en comparación con JDK 8. S
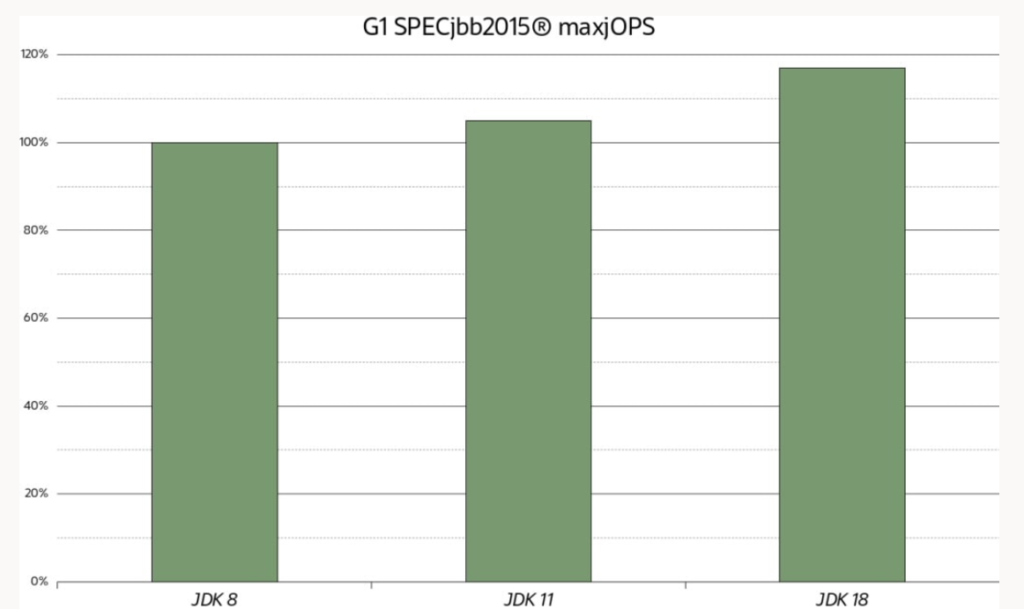
Figura 2. Ganancias de rendimiento G1 medidas con SPECjbb2015 maxjOPS
La discusión a continuación intenta atribuir estas mejoras de rendimiento a cambios particulares en la recolección de elementos no utilizados. Sin embargo, el rendimiento de la recolección de elementos no utilizados, en particular el rendimiento, también se presta a otras mejoras genéricas, como la compilación de código, por lo que los cambios en la recolección de elementos no utilizados no son responsables de todo el aumento.
Una mejora significativa al principio de JDK 9 fue cómo G1 inicia la colección de la generación anterior con pereza, lo más tarde posible.
En JDK 8, el usuario tenía que establecer manualmente la hora en que G1 comenzaba el rastreo simultáneo de objetos en vivo para la recopilación de la generación anterior. Si la hora se configuró demasiado pronto, la JVM no usó todo el montón de aplicaciones asignado a la generación anterior antes de comenzar el trabajo de recuperación. Un inconveniente fue que esto no le dio a los objetos de la generación anterior tanto tiempo para volverse recuperables. Por lo tanto, G1 no solo requeriría más recursos de procesador para analizar la vida porque todavía había más datos activos, sino que también haría más trabajo del necesario liberando memoria para la generación anterior.
Otro problema era que si el tiempo para iniciar la recopilación de la generación anterior era demasiado tarde, la JVM podría quedarse sin memoria, lo que provocaría una recopilación completa muy lenta. A partir de JDK 9, G1 determina automáticamente un punto óptimo en el que iniciar el rastreo de la generación anterior e incluso se adapta al comportamiento de la aplicación actual.
Otra idea que se implementó en JDK 9 está relacionada con tratar de recuperar objetos grandes en la generación anterior que G1 coloca allí automáticamente a una frecuencia más alta que el resto de la generación anterior. De manera similar al uso de generaciones, esta es otra forma en que GC se enfoca en el trabajo de «ganancias fáciles» que potencialmente tiene una ganancia muy alta; después de todo, los objetos grandes se llaman objetos grandes porque ocupan mucho espacio. En algunas aplicaciones (ciertamente raras), esto incluso produce reducciones tan grandes en la cantidad de recolecciones de basura y tiempos de pausa totales que G1 supera al Parallel GC en rendimiento.
En general, cada versión incluye optimizaciones que acortan las pausas de recolección de elementos no utilizados mientras se realiza el mismo trabajo. Esto conduce a una mejora natural en el rendimiento. Hay muchas optimizaciones que podrían enumerarse en este artículo, y la siguiente sección sobre mejoras de latencia señala algunas de ellas.
Al igual que en Parallel GC, G1 obtuvo reconocimiento de acceso a memoria no uniforme (NUMA) dedicado para la asignación al montón de Java en JDK 14. Desde entonces, en computadoras con múltiples sockets donde los tiempos de acceso a la memoria no son uniformes, es decir, donde la memoria está algo dedicada a los zócalos de la computadora y, por lo tanto, el acceso a cierta memoria puede ser más lento: G1 intenta explotar la localidad.
Cuando se aplica la conciencia de NUMA, el G1 GC asume que los objetos asignados en un nodo de memoria (por un solo subproceso o grupo de subprocesos) serán referenciados principalmente desde otros objetos en el mismo nodo. Por lo tanto, mientras un objeto permanece en la generación joven, G1 mantiene los objetos en el mismo nodo y distribuye uniformemente los objetos de mayor duración entre los nodos de la generación anterior para minimizar la variación del tiempo de acceso. Esto es similar a lo que implementa Parallel GC.
Una mejora más que me gustaría señalar aquí se aplica a situaciones poco comunes, siendo probablemente la más notable las colecciones completas. Normalmente, G1 intenta evitar cobros completos ajustando ergonómicamente los parámetros internos. Sin embargo, en algunas condiciones extremas esto no es posible y G1 necesita realizar una recopilación completa durante una pausa. Hasta JDK 10, el algoritmo implementado era de un solo subproceso, por lo que era extremadamente lento. La implementación actual está a la par con el proceso completo de recolección de elementos no utilizados de Parallel GC. Todavía es lento y es algo que quieres evitar, pero es mucho mejor.
Ganancias de rendimiento para el GC en paralelo. Hablando de Parallel GC, la Figura 3 muestra las mejoras en la puntuación de maxjOPS de JDK 8 a JDK 18 en la misma configuración de almacenamiento dinámico utilizada anteriormente. Nuevamente, solo al sustituir la JVM, incluso con Parallel GC, puede obtener una modesta mejora del 2 % a alrededor del 10 % en el rendimiento. Las mejoras son menores que con G1 porque Parallel GC comenzó con un valor absoluto más alto y ha habido menos que ganar.
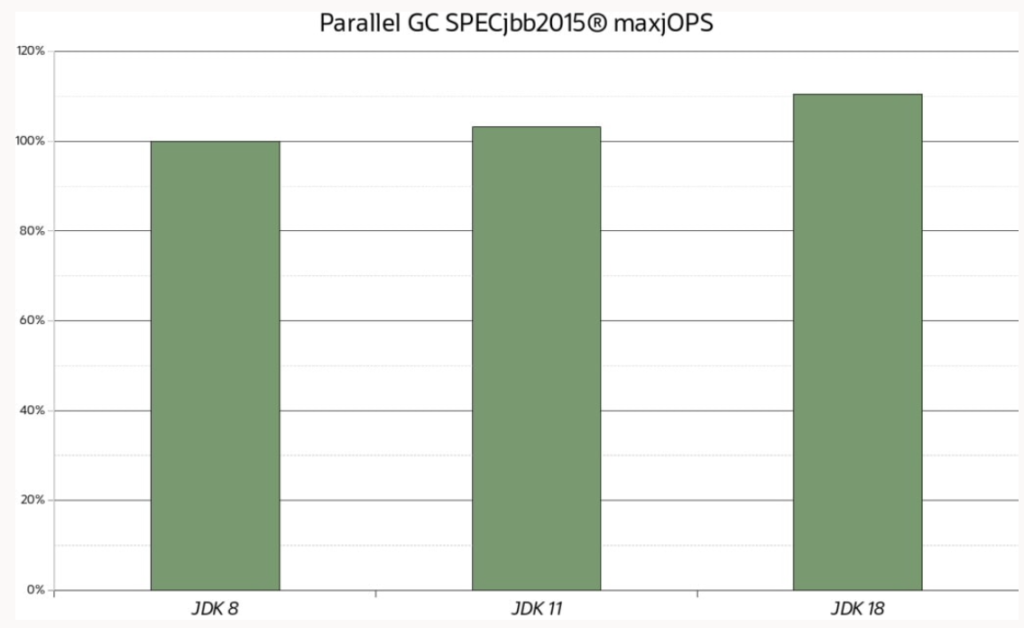
Figura 3. Ganancias de rendimiento para el GC en paralelo medido con SPECjbb2015 maxjOPS
Mejoras de latencia en G1. Para demostrar las mejoras de latencia para los GC JVM de HotSpot, esta sección utiliza el punto de referencia SPECjbb2015 con una carga fija y luego mide los tiempos de pausa. El tamaño del almacenamiento dinámico de Java se establece en 16 GB. La Tabla 2 resume los tiempos de pausa promedio y percentil 99 (P99) y los tiempos de pausa totales relativos dentro del mismo intervalo para diferentes versiones de JDK con el objetivo de tiempo de pausa predeterminado de 200 ms.
Tabla 2. Mejoras de latencia con el tiempo de pausa predeterminado de 200 ms
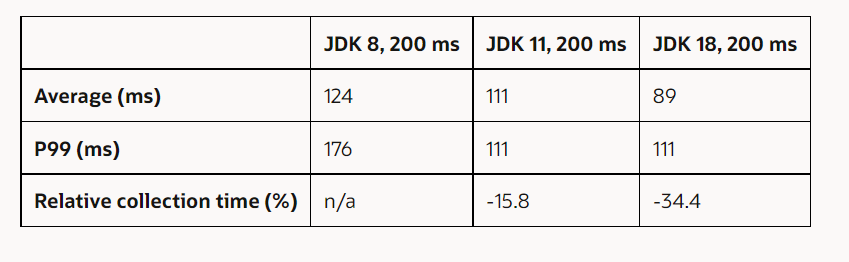
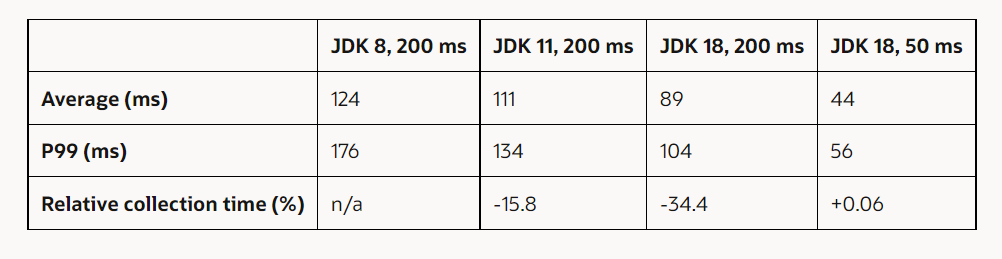
Extendí el experimento para agregar una ejecución de JDK 18 con un objetivo de tiempo de pausa establecido en 50 ms, porque decidí arbitrariamente que el valor predeterminado para -XX: MaxGCPauseMillis de 200 ms era demasiado largo. G1, en promedio, cumplió con el objetivo de tiempo de pausa, y las pausas de recolección de elementos no utilizados de P99 demoraron 56 ms (consulte la Tabla 3). En general, el tiempo total dedicado a las pausas no aumentó mucho (0,06 %) en comparación con JDK 8.
En otras palabras, al sustituir una JVM JDK 8 por una JVM JDK 18, obtiene pausas promedio significativamente menores con un rendimiento potencialmente mayor para el mismo objetivo de tiempo de pausa, o puede hacer que G1 mantenga un objetivo de tiempo de pausa mucho más pequeño (50 ms) al mismo tiempo total dedicado a las pausas, que corresponde aproximadamente al mismo rendimiento.
Tabla 3. Mejoras en la latencia al establecer el objetivo de tiempo de pausa en 50 ms
Una contribución bastante grande a la reducción de la latencia fue la reducción de los metadatos necesarios para recopilar partes de la generación anterior. Los llamados conjuntos recordados se han recortado significativamente tanto por mejoras en las propias estructuras de datos como por no almacenar y actualizar información que nunca se necesita. En las arquitecturas informáticas actuales, una reducción de los metadatos a administrar significa mucho menos tráfico de memoria, lo que mejora el rendimiento.
Otro aspecto relacionado con los conjuntos recordados es el hecho de que el algoritmo para encontrar referencias que apuntan a áreas actualmente evacuadas del montón se ha mejorado para que sea más susceptible a la paralelización. En lugar de examinar esa estructura de datos en paralelo e intentar filtrar los duplicados en los bucles internos, G1 ahora filtra por separado los duplicados del conjunto recordado en paralelo y luego paraleliza el procesamiento del resto. Esto hace que ambos pasos sean más eficientes y mucho más fáciles de paralelizar.
Además, el procesamiento de estas entradas de conjuntos recordados se ha analizado minuciosamente para recortar el código innecesario y optimizar las rutas comunes.
Otro enfoque en los JDK posteriores a JDK 8 ha sido mejorar la paralelización real de las tareas dentro de una pausa: los cambios han intentado mejorar la paralelización haciendo que las fases sean paralelas o creando fases paralelas más grandes a partir de las seriales más pequeñas para evitar puntos de sincronización innecesarios. Se han gastado recursos significativos para mejorar el equilibrio del trabajo dentro de las fases paralelas, de modo que si un subproceso no tiene trabajo, debería ser más inteligente al buscar trabajo para robar de otros subprocesos.
Por cierto, los JDK posteriores comenzaron a buscar situaciones menos comunes, una de ellas fue la falla de evacuación. La falla de evacuación ocurre durante la recolección de basura si no hay más espacio para copiar objetos.
La recolección de basura se detiene en ZGC. En caso de que su aplicación requiera tiempos de pausa de recolección de basura aún más cortos, la Tabla 4 muestra una comparación con uno de los recopiladores centrados en la latencia, ZGC, en la misma carga de trabajo utilizada anteriormente. Muestra las duraciones del tiempo de pausa presentadas anteriormente para G1 más una columna adicional a la derecha que muestra ZGC.
Tabla 4. Latencia de ZGC en comparación con la latencia de G1

ZGC cumple su promesa de objetivos de tiempo de pausa de submilisegundos, moviendo todo el trabajo de recuperación de forma simultánea a la aplicación. Solo algunos trabajos menores para proporcionar el cierre de las fases de recolección de basura aún necesitan pausas. Como era de esperar, estas pausas serán muy pequeñas: en este caso, incluso muy por debajo del rango de milisegundos sugerido que ZGC pretende proporcionar.
Mejoras en la huella para G1. La última métrica que examinará este artículo es el progreso en la huella de memoria del algoritmo de recolección de elementos no utilizados G1. Aquí, la huella del algoritmo se define como la cantidad de memoria adicional fuera del montón de Java que necesita para proporcionar su funcionalidad.
En G1, además de los datos estáticos que dependen del tamaño del almacenamiento dinámico de Java, que ocupa aproximadamente el 3,2% del tamaño del almacenamiento dinámico de Java, a menudo se recuerda que el otro consumidor principal de memoria adicional son los conjuntos que permiten la recolección de basura generacional y, en particular, recolección de basura incremental de la vieja generación.
Una clase de aplicaciones que hace hincapié en los conjuntos recordados de G1 son los cachés de objetos: con frecuencia generan referencias entre áreas dentro de la generación anterior del montón a medida que agregan y eliminan entradas recién almacenadas en caché.
La figura 4 muestra los cambios en el uso de la memoria nativa de G1 de JDK 8 a JDK 18 en una aplicación de prueba que implementa una caché de objetos de este tipo: los objetos que representan información almacenada en caché se consultan, agregan y eliminan de una manera menos utilizada recientemente de un montón grande. Este ejemplo utiliza un montón de Java de 20 GB y utiliza la función de seguimiento de memoria nativa (NMT) de JVM para determinar el uso de la memoria.
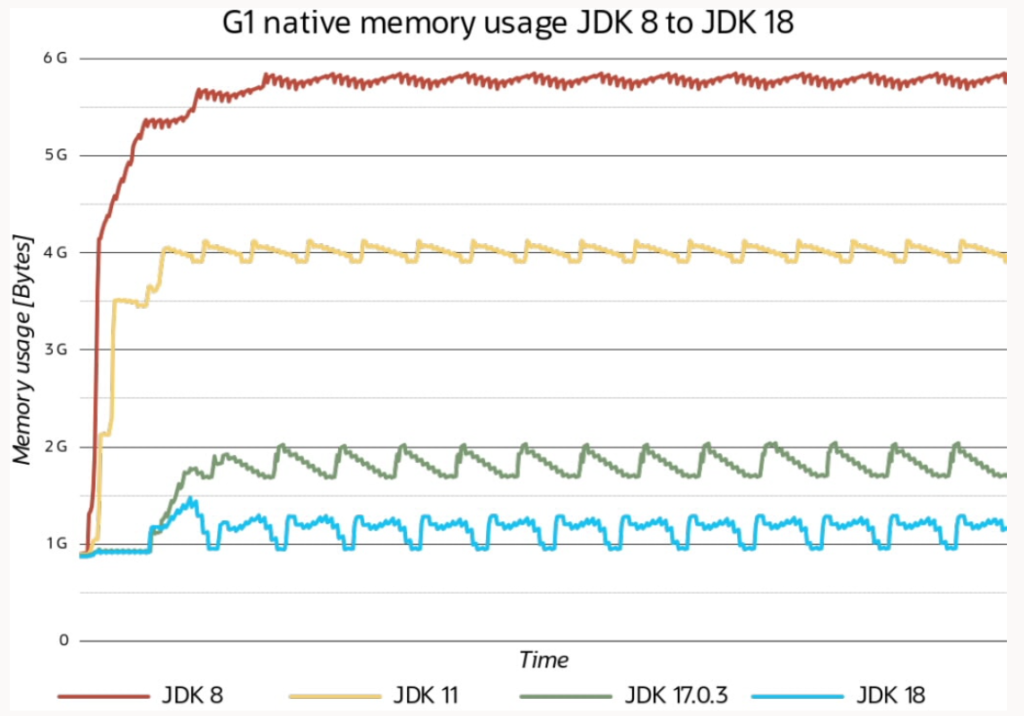
Con JDK 8, después de un breve período de preparación, el uso de la memoria nativa G1 se establece en alrededor de 5,8 GB de memoria nativa. JDK 11 mejoró eso, reduciendo la huella de memoria nativa a alrededor de 4 GB; JDK 17 lo mejoró a alrededor de 1,8 GB; y JDK 18 se establece en alrededor de 1,25 GB de uso de memoria nativa de recolección de elementos no utilizados. Esta es una reducción del uso de memoria adicional de casi el 30 % del montón de Java en JDK 8 a alrededor del 6 % del uso de memoria adicional en JDK 18.
No hay un costo particular en rendimiento o latencia asociado con estos cambios, como se mostró en las secciones anteriores. De hecho, la reducción de los metadatos que mantiene el G1 GC generalmente mejoró las otras métricas hasta ahora.
El principio principal de estos cambios de JDK 8 a JDK 18 ha sido mantener los metadatos de recolección de elementos no utilizados solo de manera muy estricta según sea necesario, manteniendo solo lo que se espera que se necesite cuando se necesita. Por esta razón, G1 recrea y administra esta memoria al mismo tiempo, liberando datos lo más rápido posible. En JDK 18, las mejoras en la representación de estos metadatos y su almacenamiento más denso contribuyeron significativamente a la mejora de la huella de memoria.
La Figura 4 también muestra que en versiones posteriores de JDK, G1 aumentó su agresividad, paso a paso, al devolver memoria al sistema operativo al observar la diferencia entre picos y valles en operaciones de estado estable; en la última versión, G1 incluso hace esto. proceso simultáneamente.
El futuro de la recolección de basura
Aunque es difícil predecir lo que depara el futuro y lo que proporcionarán los muchos proyectos para mejorar la recolección de basura y, en particular, G1, es más probable que algunos de los siguientes desarrollos terminen en HotSpot JVM en el futuro.
Un problema en el que se está trabajando activamente es eliminar la necesidad de bloquear la recolección de elementos no utilizados cuando los objetos de Java se usan en código nativo: los subprocesos de Java que desencadenan una recolección de elementos no utilizados deben esperar hasta que ninguna otra región tenga referencias a objetos de Java en código nativo. En el peor de los casos, el código nativo puede bloquear la recolección de elementos no utilizados durante minutos. Esto puede llevar a que los desarrolladores de software decidan no utilizar ningún código nativo, lo que afectaría negativamente al rendimiento. Con los cambios sugeridos en JEP 423 (Region pinning for G1), esto dejará de ser un problema para el G1 GC.
Otra desventaja conocida de usar G1 en comparación con el colector de rendimiento, Parallel GC, es su impacto en el rendimiento: los usuarios informan diferencias en el rango del 10 % al 20 % en casos extremos. Se conoce la causa de este problema y ha habido algunas sugerencias sobre cómo mejorar este inconveniente sin comprometer otras cualidades del G1 GC.
Recientemente, se ha determinado que los tiempos de pausa y, en particular, la eficiencia de la distribución del trabajo en las pausas de recolección de basura aún no son óptimas.
Un foco de atención actual es eliminar la mitad de la estructura de datos de ayuda más grande de G1, los mapas de bits de marcas. Hay dos mapas de bits utilizados en el algoritmo G1 que ayudan a determinar qué objetos están activos actualmente y G1 puede inspeccionarlos de manera segura y simultánea en busca de referencias. Una solicitud de mejora abierta indica que el propósito de uno de estos mapas de bits podría reemplazarse por otros medios. Eso reduciría inmediatamente los metadatos G1 en un 1,5 % fijo del tamaño del almacenamiento dinámico de Java.
Hay mucha actividad en curso para cambiar los GC ZGC y Shenandoah para que sean generacionales. En muchas aplicaciones, el diseño actual de una sola generación de estos GC tiene demasiadas desventajas con respecto al rendimiento y la puntualidad de la recuperación, lo que a menudo requiere tamaños de montón mucho más grandes para compensar.
Conclusión
Este artículo ha demostrado que las mejoras en los algoritmos de recolección de elementos no utilizados de HotSpot JVM de JDK 8 a JDK 18 han sido significativas, ya que los tres indicadores de rendimiento (rendimiento, latencia y huella de memoria) mejoraron en cantidades no triviales. Cada nueva versión de JDK, incluso si no señalaba explícitamente dichas mejoras en los JEP, proporcionaba mejoras tangibles. Es probable que siga siendo así en el futuro previsible, ¡así que manténgase actualizado y disfrute de las mejoras gratuitas!
Gracias a los muchos colaboradores de OpenJDK que hicieron posible todas estas grandes mejoras con el tiempo.